


Large language models don’t emerge from thin air; they’re shaped by editorial decisions, licensing deals, and distribution networks. When an AI company signs a content deal with a publisher group (or crawls one heavily), that partnership doesn’t just fill a training set. It rearranges neighborhoods in the model’s latent space. Over time, those neighborhoods harden into a de facto knowledge graph: the people, brands, and ideas that an assistant “knows,” how they are connected, and which sources it trusts when answering your customers.
Today’s AI media partnerships act like gravity. They pull certain outlets closer to the center of answers and push others to the margins. If your brand appears often in those center-of-gravity outlets, assistants see more of you. If not, you risk being summarized, paraphrased, or simply outranked by competitors who are.
Our analysis of publisher presence across major assistants and AI Overviews shows a concentrated field. WebMD, BBC, Forbes, Business Insider, and People top overall AI citation volume — clear evidence that a handful of brands are disproportionately shaping what gets retrieved and repeated across bots. At the same time, the major model companies are forging broad, named AI publisher partnerships that set the boundaries of what content is both available and legally “quiet” for training and retrieval.
This isn’t just media strategy anymore. It’s model strategy. Brands that plan for this reality by placing stories where models see them, and by publishing assets models weigh up, will earn disproportionate reach inside the answers customers trust.
Key Takeaways
- Five publishers dominate AI visibility overall. Across AI Overviews (AIOs) and major LLMs, WebMD (~1.2M AI citations), BBC (~489.6K), Forbes (~468.2K), Business Insider (~397.8K), and People (~345.2K) are the most present.
- Model-by-model “favorites” differ. In ChatGPT, Forbes leads (~202K citations), with Wired and The Guardian close behind. Perplexity leans into WebMD and Forbes, Copilot tilts to Forbes and MSN, and Gemini surfaces WebMD and CNET early and often.
- Vertical winners are stable and actionable. All Recipes dominates food across models, U.S. News leads travel and education, and Economic Times tops business. Yahoo anchors lifestyle, and the New York Post commands tech within ChatGPT.
- Partnerships set the playing field. OpenAI’s network spans Axel Springer, News Corp, FT Group, The Atlantic, TIME, Guardian Media Group, and more. Microsoft ties include Thomson Reuters, FT Group, Axel Springer, Gannett, and Hearst. Perplexity lists TIME, Fortune, DER SPIEGEL, Texas Tribune, Automattic, and others. These AI media partnerships influence what gets ingested, retrieved, and cited.
- What GenAI “trusts” most isn’t guesswork. Our forecast heatmap scores peer-reviewed journals and open-source code the highest on training value. SEO blogspam, AI-ghostwritten fiction, and fake reviews sit at the bottom. Prioritize placements and assets that resemble what models intrinsically weigh up.
What We Mean by “AI Media Partnerships” (and How They Shape Latent Space)
When we say “AI media partnerships” or “AI publisher partnerships,” we mean licensing and access agreements between model providers and publishers. These deals influence three levers that structure a model’s internal map:
- Coverage: which archives are lawfully available, deeply crawled, and refreshed
- Context: how frequently those sources appear in pretraining corpora, RAG indexes, eval sets, and safety/red-team workflows
- Credibility: how the system ranks and cross-checks sources at answer time
When a publisher network joins a model’s partner list, it becomes easier for that model to ingest, attribute, and confidently reuse the network’s content. Over time, those sources become “landmarks” in the model’s knowledge graph, anchoring entities (including your brand) with stronger, more retrievable signals. Today’s partner webs are broad and named, spanning international news groups, lifestyle conglomerates, and specialist titles, giving them a structural advantage at the exact moment assistants are standardizing their answer supply chains.
Brand implication: If your narrative predominantly lives outside these partner webs, you’ll work harder (and pay more) to be found, quoted, or summarized faithfully by AI assistants.
LLM and Publisher Partnerships
The center of gravity in generative AI isn’t just model architecture or GPU spend. It’s the content supply chain. AI media partnerships (or AI publisher partnerships) determine which archives are easiest to ingest, attribute, and legally reuse, and that in turn shapes what assistants retrieve when they talk about your industry and brand.
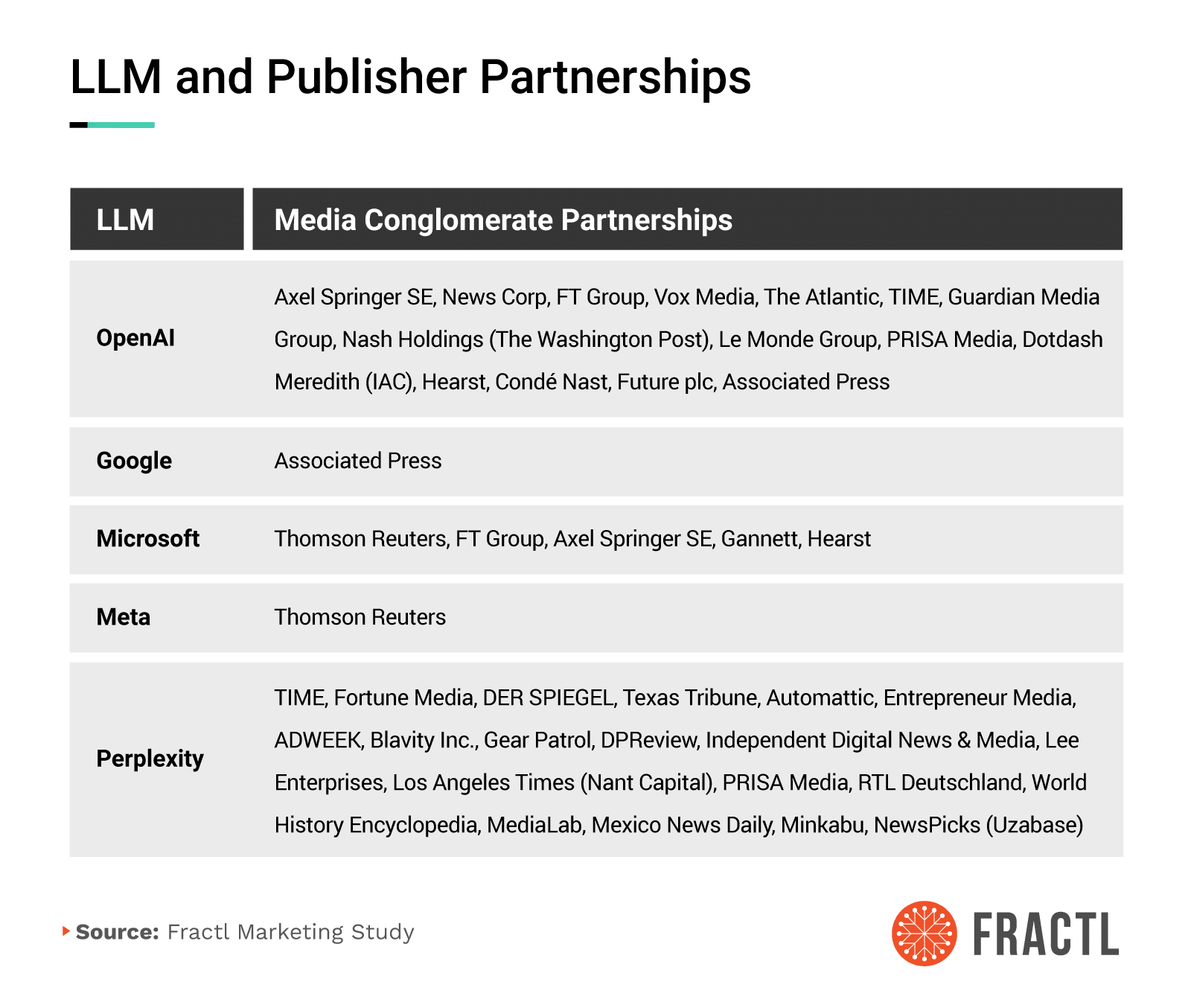
OpenAI’s public and reported network now spans global news groups and lifestyle conglomerates including: Axel Springer SE, News Corp, FT Group, Vox Media, The Atlantic, TIME, Guardian Media Group, Nash Holdings (The Washington Post), Le Monde Group, PRISA Media, Dotdash Meredith (IAC), Hearst, Condé Nast, Future plc, and the Associated Press. This gives OpenAI breadth across international news, business, tech, culture, and lifestyle.
Microsoft highlights ties with Thomson Reuters, FT Group, Axel Springer SE, Gannett, and Hearst, while Google cites the Associated Press, and Meta has ties with Thomson Reuters. This signals that multiple assistants are standardizing around large, legally clean archives with strong editorial controls.
Meanwhile, Perplexity has assembled a broad coalition of: TIME, Fortune Media, DER SPIEGEL, Texas Tribune, Automattic, Entrepreneur Media, ADWEEK, Blavity Inc., Gear Patrol, DPReview, Independent, Lee Enterprises, Los Angeles Times (Nant Capital), PRISA Media, RTL Deutschland, World History Encyclopedia, MediaLab, Mexico News Daily, Minkabu, and NewsPicks. Clearly, Perplexity is tilting its corpus toward magazine features, specialty verticals, and regional depth.
OpenAI Publisher Partner Web
OpenAI’s partner web is best understood as a federated newsroom: multiple conglomerates with different editorial philosophies and vertical specialties, bound together by licensing and interoperability.
- Axel Springer contributes international news and business depth.
- News Corp spans finance, general news, and culture.
- FT Group adds high-signal economics and markets coverage.
- The Atlantic and TIME inject long-form analysis and ideas journalism.
- Guardian Media Group and Le Monde Group broaden European public-interest reporting.
- Dotdash Meredith, Hearst, Condé Nast, and Future plc bring lifestyle, health, and service journalism at scale.
- The Associated Press anchors the wire layer for fast verification and syndication.
Most Present Publishers in Each Chatbot
Across assistants, a small cluster of outlets acts like source gravity, with answers tending to start from the same editorial cores before branching out. In aggregate, WebMD, BBC, Forbes, Business Insider, and People surface most often, creating a baseline tone for how brands and categories are framed across bots.
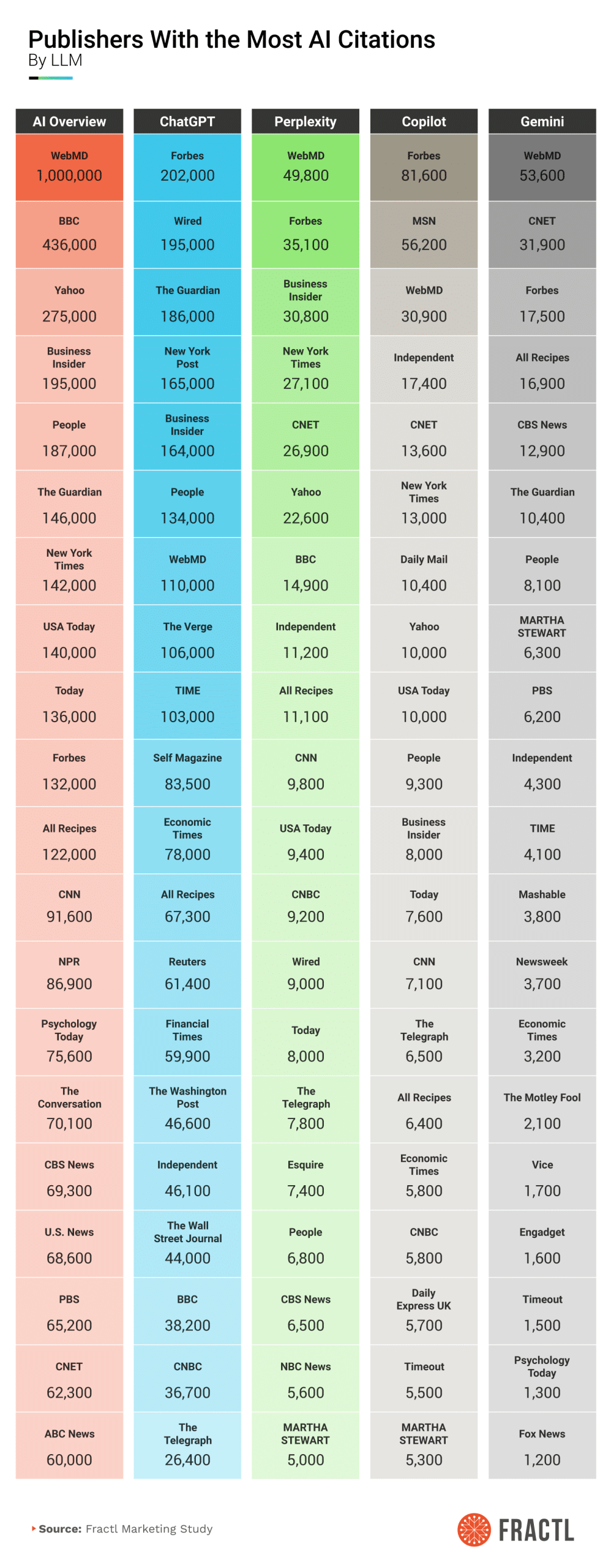
Within that baseline, each assistant follows its own “source diet.” Some lean into business and general news (more deal flow, constant updates), while others elevate reference-grade health and service journalism (evergreen, highly structured). For planning, treat these as model-specific answer corridors: Map which titles each bot prefers, then target your flagship placements accordingly.
Most Present Publisher by Vertical in Each Chatbot
Zooming into verticals, assistants repeatedly anchor on a few publications of record per industry. Health, education, travel, business, tech, and lifestyle each show durable leaders. That dynamic is useful. You don’t need omnipresence; you need canonical presence in the two or three titles that consistently define your vertical inside each bot.
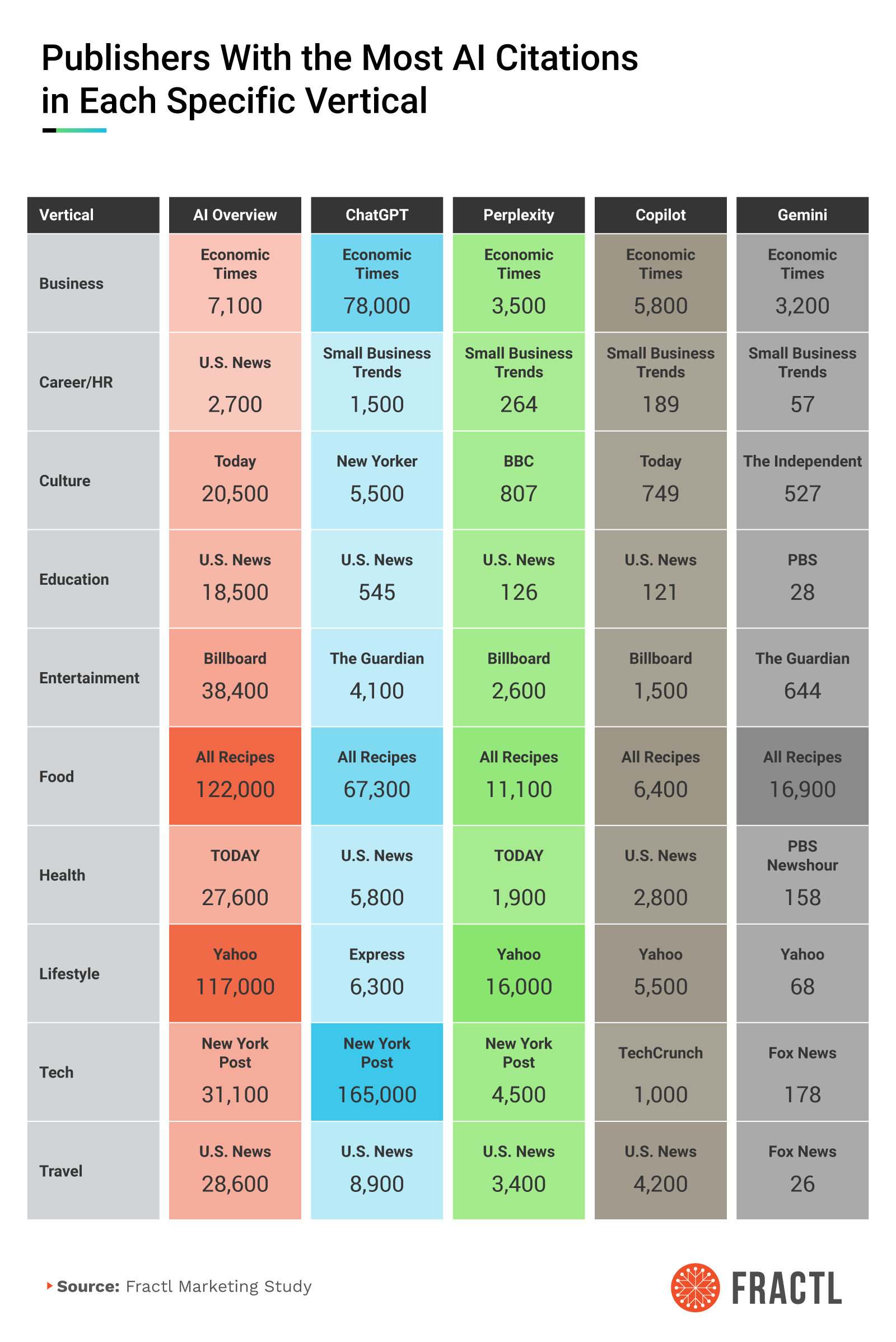
Pair that placement strategy with awareness of AI media partnerships/AI publisher partnerships. When a vertical leader also sits inside a model’s partner web, its content travels a cleaner path into training, grounding, and attribution, compounding your odds of being summarized faithfully.
Who Does Generative AI Trust?
When assistants “decide” which facts to reuse or cite, they aren’t guessing. They lean on source types that are rare enough to carry signals, documented enough to verify, and clean enough to use at scale.
In our framework, the sources that repeatedly sit near the top are:
- Peer-reviewed journals
- Patents and standards
- University materials
- Court and government transcripts
- Investigative journalism
- Open-source code
Lower on the spectrum are surfaces that are easy to game or hard to audit, including SEO blogspam, AI-ghostwritten fiction, fake reviews, clickbait wires, and ephemeral social chatter.
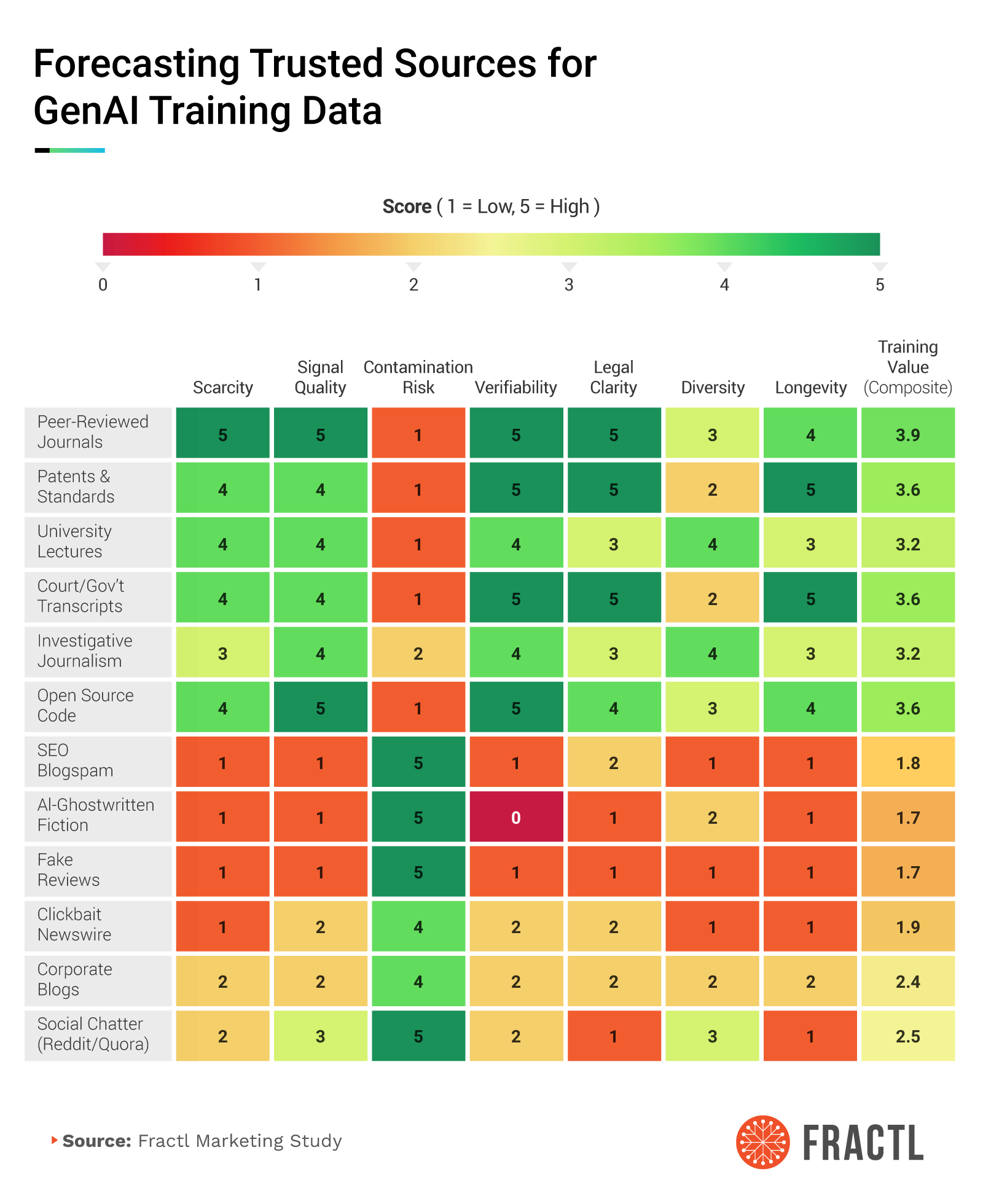
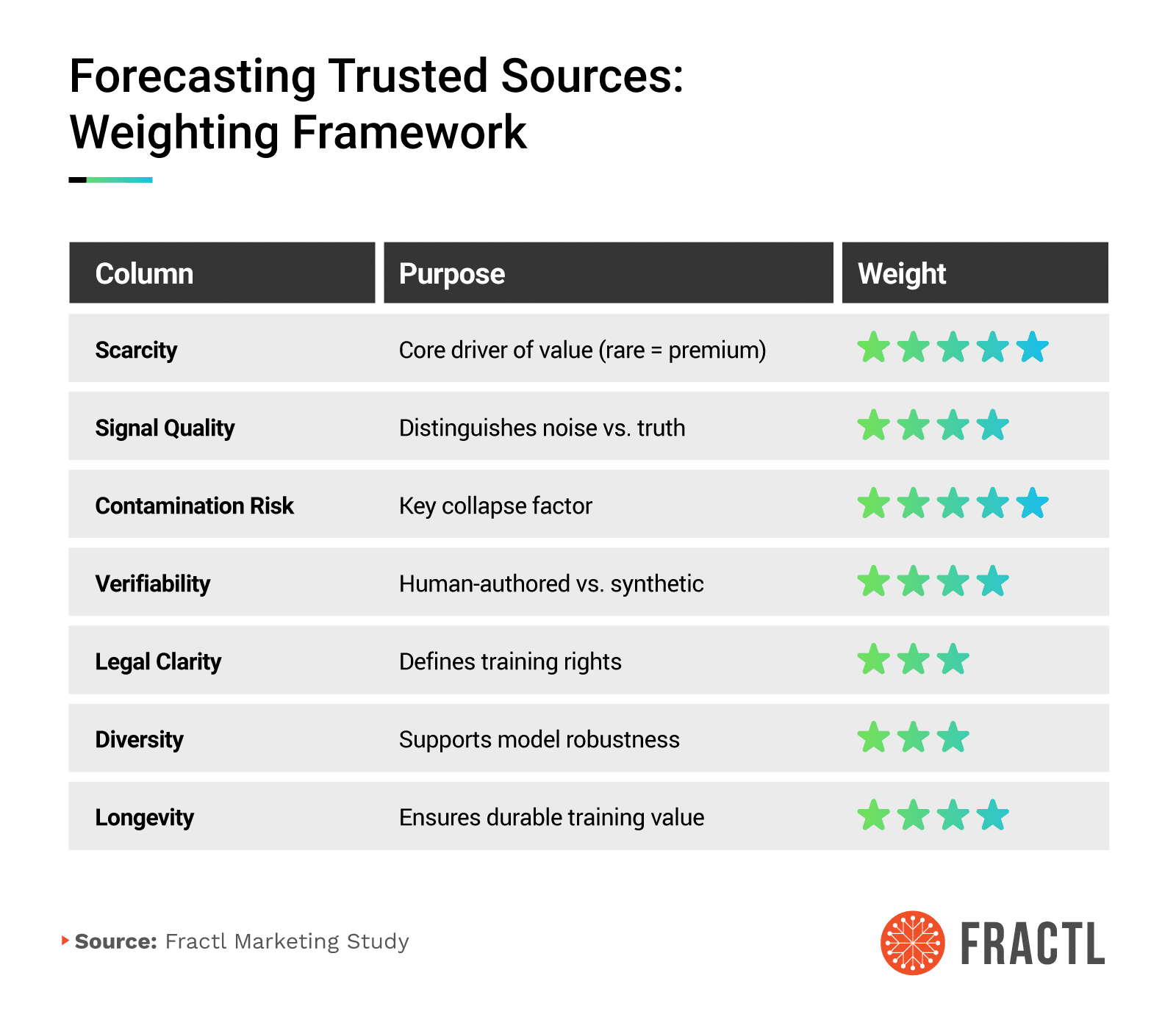
Under the hood, we scored sources along seven practical dimensions:
- Scarcity captures how hard the content is to replicate (rare = premium).
- Signal quality distinguishes truth from noise.
- Contamination risk penalizes synthetic or derivative material that can collapse training.
- Verifiability favors human-authored, citable work with transparent methods.
- Legal clarity determines whether content can be confidently trained on or grounded against.
- Diversity rewards breadth across authors, topics, and perspectives.
- Longevity prioritizes assets that remain useful across model updates.
Together, these created a composite “training value” signal that aligns closely with how assistants assemble answers. The higher the score, the more valuable the source.
For brands, the translation is straightforward but high-leverage:
- Publish model-ready assets like original datasets, reproducible methods, and code or appendices that make verification trivial.
- Host them on stable URLs, with descriptive H1s and clear claims that external outlets can quote cleanly.
- Pair major launches with AI publisher partnerships outreach so that your high-weight assets are discoverable inside the very networks assistants already prefer to crawl, ground, and cite.
Over time, these signals compound. Credible citations from partner outlets point back to your canonical pages, which increases the odds that assistants reuse your language and numbers verbatim.
A final note on risk: Thin, derivative, or ambiguously licensed content doesn’t just underperform. It can drag your brand toward lower-trust neighborhoods in the model’s latent space. Aim for scarce + verifiable + cleanly licensed as the default. That’s how you earn durable presence inside answers, not just fleeting mentions on the open web.
Conclusion
AI assistants start from who they can see and trust. A handful of publishers set the tone across bots, and within each industry, a few titles act as landmarks. Win mentions in those publications, and you nudge the latent space itself.
The playbook is straightforward: Align placements with the outlets each assistant favors, leverage AI media partnerships/AI publisher partnerships to move your stories onto the cleanest distribution rails, and publish primary, verifiable assets that models weigh up. Do that consistently, and you won’t just earn media coverage — you’ll earn presence inside the AI answers your customers rely on.
Methodology
For this study, we leveraged Ahrefs to analyze the number of AI citations for mainstream publications across different LLMs.
For the initial breakdown, we gathered AI citation data for 102 publications across various verticals using the publications’ root domain. On average, the DA of these publications was 92, with an average monthly organic traffic of 10.1 million and over 40 million backlinks.
For the vertical specific breakdown, we gathered AI citation data across 250 vertical-specific domains, specifically 25 publishers for each of 10 verticals. On average, the DA of the publications analyzed for each vertical was over 90.
About Fractl
Fractl is a growth marketing agency that helps brands earn attention and authority through data-driven content, digital PR, and AI-powered strategies. Our work has been featured in top-tier publications, including The New York Times, Forbes, and Harvard Business Review. With over a decade of experience, we’ve helped clients across industries achieve measurable results, from skyrocketing organic traffic to building lasting brand trust.
Fractl is also the team behind Fractl Agents, where we develop advanced AI workflows to push the boundaries of marketing and automation. This hands-on experience at the frontier of generative AI informs our research, ensuring our insights are grounded in both data and practice.
Fair Use Statement
If you’d like to reference or republish findings from this study, please link back to Fractl and cite the source. For press inquiries or bespoke cuts (by sub-vertical or region), contact us.

